Descenso por gradiente
Descenso por gradiente es el método por el cual las redes neuronales aprenden. Se basa en alcanzar el mínimo de la función de error (o funcíon de coste). Recordemos que esta función es la que comparaba la salida real con la salida esperada, y mide cuánto error tiene la red para sus diferentes configuraciones de pesos.
- Si sólo tiene 1 peso la gráfica sera en 2D (el peso y el error)
- Si tiene 2 pesos la gráfica será en 3D (los 2 pesos y el error)
- Pero en la práctica la red neuronal tiene muchos pesos y no podemos visualizar dicha función
También se pueden entrenar otros modelos como regresiones lineales o máquinas de vectores de soprote con descenso por gradiente (de hecho, es común hacerlo cuando se tienen muchos datos). Solo que calcualar el gradiente para las redes neurnales es ligeramente más complicado. (pero se puede calcucualr de forma eficiente y precisa). La sección 6.5 explica como hacerlo usando el algortimo de back-propagation.
Los algoritmos de machine learning cuyos modelos son lineales (como regresiones lineales) su función de error es convexa, esto quiere decir que siempre (en teoría) alcanzan el mínimo global y da igual el punto inicial de sus parámetros
En cambio, el descenso por gradiente en modelos no lineales, como las redes neuronales, no asegura alcanzar el mínimo global ya que puede quedares en un mínimo local. Por lo tanto la inicilaización de los parámetros (los pesos) es importante ya que determina el punto inicial del descenso por gradiente.
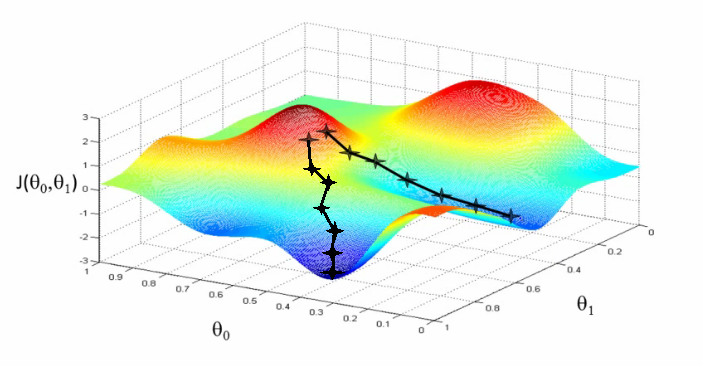
En la práctica es importante inicializar los peosos de la red a valores aleatorios pequeños. Y los bias a cero o valores positivos pequeños. Más optimizaciones del descenso por gradiente se ven en el capítlo 8.
Función de coste
sum-squared error: J(w) = 1/2 sumatorio (y-y')^2
mean-squared error: J(w) = 1/n sumatorio (y-y')^2
Cross-entropy
Tipos de gradient descent
a ver, hay 3 tipos de gradient descent:
- stochastic batchSize=1
- batch batchSize=todo
- mini-batch batchSize=parte
Stochastic gradient descent (SGD)
Se actualiza el modelo por cada muestra que ve (batchSize=1)
Batch gradient descent
Se ven todos los datos, pero solo se actuliza el modelo al final de la epoch (batchSize=todo)
Mini-batch gradient descent
Se cogen solo un grupo de muestras (batch) y se actualiza el modelo cuando se han visto esas muestras (batchSize=parte).
Se hacen varias interaciones por cada batch hasta que se vean todas las mustras (completar una epoch). el tamaño del últomo bach creo que debe ser mas pequeño para poder así compleatar la epoch.
Referncias
https://machinelearningmastery.com/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/