Capsule netwoks
Parte 1: Introducción al problema
Resumen
- Es una idea de Geoffrey E. Hinton.
- El objetivo Ser invariante a la posición en el reconocimiento de imágenes.
- En lugar de añadir mas capas, pone “capas dentro de otras”.
Problemas de las CNNs
Aunque las redes convolucionales funcionan bastante bien en el reconocimiento de imágenes, tienen algunos puntos débiles.
Una CNNs funciona de la sigiente manera:
1) En las primeras capas busca patrones simples como bordes. 2) Con los patrones encontrados, buscar patrones más complejos como ojos. 3) Con los patrones complejos encontrados, busca patrones todavía más complejos como caras.
Problema 1: Distribución espacial
El poblema es que aunque sigue una jerarquía correcta, se va perdiendo la distribución espacial de los patrones. Y puede pensar que ve una cara cuando ve ojos y boca. Es un problema de falso positivo.
Max pooling soluciona un poco este problema??
Problema 2: Rotar e invertir la imagen
Este es otro gran problema debido a que las imagenes que se usan para entrenar, suelen tener simpre en la misma posición. Por lo tanto los filtros se aprenderán para ese enfoque. Asi que conforme rotamos la imagen, la CNN dejará de predecir lo que ve. Es un problema de falso negativo.
Una solución común es utilizar imagenes con distista rotación al entrenar la red, pero esto implica aprender los mismos patrones para diferentes posiciones, una solución algo ineficiente en cuanto el numero de patrones a aprender.
Problema 3: Hackeo de pixeles –necesario??
Además exite un tercer problema (inherente a todas las redes neuronales pero que afecta especialmete a las CNNs) que consiste en modificar lijeramente la imagen para engañar a la red neuronal. Esta modificación consiste en buscar y modificar algunos pixeles de forma concienzuda para engañar a la red, pero visaulmente la imagen no cambia casi nada para un humano. Es un problema de falso negativo.
Conclusión de las CNNs
Debido a estos 3 problemas, Hinton dice que las CNNs están condenadas. Y propone las Capsule netwoks
“Convolutional neural networks are doomed” — Geoffrey Hinton
Prece que vamos a resolver solo el problema 1
Segun Hinton,
“The pooling operation used in convolutional neural networks is a big mistake and the fact that it works so well is a disaster.”
Por supuesto que se puede quitar el pooling, y la CNNs seguirá funcionano bien.
Vídeo de la charla donde Hilton explica porquá las CNNs funcionan mal.
Representción interna de un mundo 3D
Los programas de edición 3D que guardan los objetos en 3D (la posición relativa entre los puntos) y cuando hacen render, visualizan el objeto 3D en una imagen 2D.
Hinton afirma que el cerebro hace el proceso inverso al render, es decir, formar el mapa 3D a partir de la imagen en 2D. Probablente analizar jeraqucamente los patrones de la imagen (como hacen las CNNs) pero va un poco más allá: Hay que intentar hacer coincidir esos patrones con los patrones 3D que tenemos aprendidos.
La clave es darse cuenta que la representación de objetos en el cerebro no depende del ángulo de visión.
Hilton afirma que para reconocer objetos de forma correcta, es importante mantener las relaciones jerárqicas de posición entre las partes de un objeto.
De esta manera, el roconociento de un objeto podrá ser corrrecto en todas sus posiciones.
Aqui hago un inciso de como se representa la posición de un objeto de forma matemática y usaado en los grogramas de diseño 3D
Representación matemática de la posición
La posición de un obejeto depende de 2 cosas: dónde se ubica (translación) y en qué posición se encuentra (rotación). Matemáticamente se puede expresar de la siguiente manera:
- Traslación: vector de tamaño 3, donde se indica la traslación en cada eje (x,y,z)
- Rotación: matriz de tamaño 3x3, donde se expresa ¿¿??
Para definir la posición final, se juntan los 2 parámteros en una matriz de tamaño 4x4. Leer este link
Actualmete las CNN aprenden la forma 2D de los objetos (lo mejor que pueden) Pero si aprendiesen la forma 3D y además les facilitamos esta matriz de posión ¡serían capaces de reconoder un objeto en un imagen 2D desde cualquier ángulo!

Hemos dicho que los pooling pierden información relevante, y además si empezamos a girar la imagen, la cnn empieza a fallar.
Parte 2: Como funcionan las cápsulas
Funcionamiento de las capsulas
Una cápsula es reponsable de detectar una característica-patrón, al igual que un filtro de una CNN.
Pero la salida de una cápsula no es un scalar, es un vector. Este vector codifica información relevante a la posción de la característica-patrón
Es decir, en lugar de dar solo la probabilidad de ver un patrón (un escalar), como hacen las redes convolucionles. Las cápsulas devuelven la probabilidad de ver un patrón (un escalar) + la posición-orientación de dicho patrón (un vector).
Luego la salida de la cápsula codifica:
- La probabilidad de detectar una característica-patrón (un número) (es la longitud espacial del vector Estado, creo)
- La posición-estado-orientación en que se encuentra dicho patrón (un vector Estado)
Asi que cuando el objeto (o mejor dicho una característica-patrón de un ojeto) que estmos detectando se mueve (rota o traslada), la probabilidad seguirá siendo la misma (la longitud del vector en el espacio no cambia), pero la orientación del vector cambia.
Un ejemplo
Imagina una cápsula que detecta una cara, si movemos la cara dentro de la imagen, el vector rotará en su espacio, pero su longitud se mantedrá fija. A esto es lo que se refiere Hilton con equivariance.
- equivariance: La actividad neuronal cambirá si movemos-rotamos el objeto
- invariance: La actividad neuronal es independiente de si movemos-rotamos el objeto
Sugún Hilton, equivariance es mejor porque proporciona más información, es decir, la red será consciente de en que posición se encutra el objeto. Esto es mejor respecto una red invariante, es decir, que es ciega respecto a la pose del objeto, como pasa en las CNNs.
Computación numérica
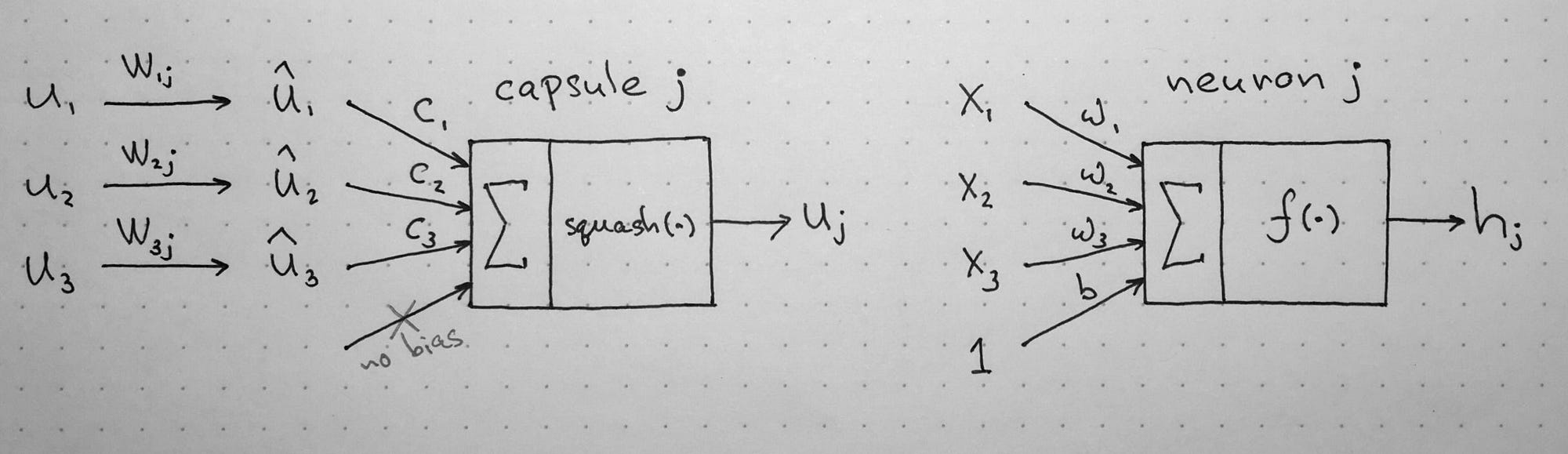
Neurona tradicional (las entradas y salidas son escalares)
- multiplicar las entradas por los pesos
- Sumar
- Función de activación (scalar-to-scalar nonlinearity)
Cápsula (las entradas y salidas son vectores)
- Multiplicación de los vectrores de entrada por una matriz de Transformación
- Multiplicación escalar por los pesos
- Sumar los vectores
- Función de activación (vector-to-vector nonlinearity)
Paso 0
Los vectores de entrada son a su vez vectores de salida de alguna capa anterior.
Resumiendo
*
- La salida de cápsulas que en forma de vector.
Parte 3: Como se entrenan las capsule networks
El algoritmo de entrenamiento es Dynamic Routing Between Capsules
Más información
Oficial
Medium
- Understanding Hinton’s Capsule Networks. Part I: Intuition.
- Understanding Hinton’s Capsule Networks. Part II: How Capsules Work.
- Understanding Hinton’s Capsule Networks. Part III: Dynamic Routing Between Capsules.
- A Visual Representation
- Capsule Networks Are Shaking up AI